*click the video to play again!
LR refers to low-resolution training, and Ours represents the x4 upsampled image. It was upsampled using our ALS (Adaptive Length Sequencing) and trained with 3DGS.
3D super-resolution aims to reconstruct high-fidelity 3D models from low-resolution (LR) multi-view images. Early studies primarily focused on single-image super-resolution (SISR) models to upsample LR images into high-resolution images. However, these methods often lack view consistency because they operate independently on each image. Although various post-processing techniques have been extensively explored to mitigate these inconsistencies, they have yet to fully resolve the issues. In this paper, we perform a comprehensive study of 3D super-resolution by leveraging video super-resolution (VSR) models. By utilizing VSR models, we ensure a higher degree of spatial consistency and can reference surrounding spatial information, leading to more accurate and detailed reconstructions. Our findings reveal that VSR models can perform remarkably well even on sequences that lack precise spatial alignment. Given this observation, we propose a simple yet practical approach to align LR images without involving fine-tuning or generating `smooth' trajectory from the trained 3D models over LR images. The experimental results show that the surprisingly simple algorithms can achieve the state-of-the-art results of 3D super-resolution tasks on standard benchmark datasets, such as the NeRF-synthetic and MipNeRF-360 datasets.
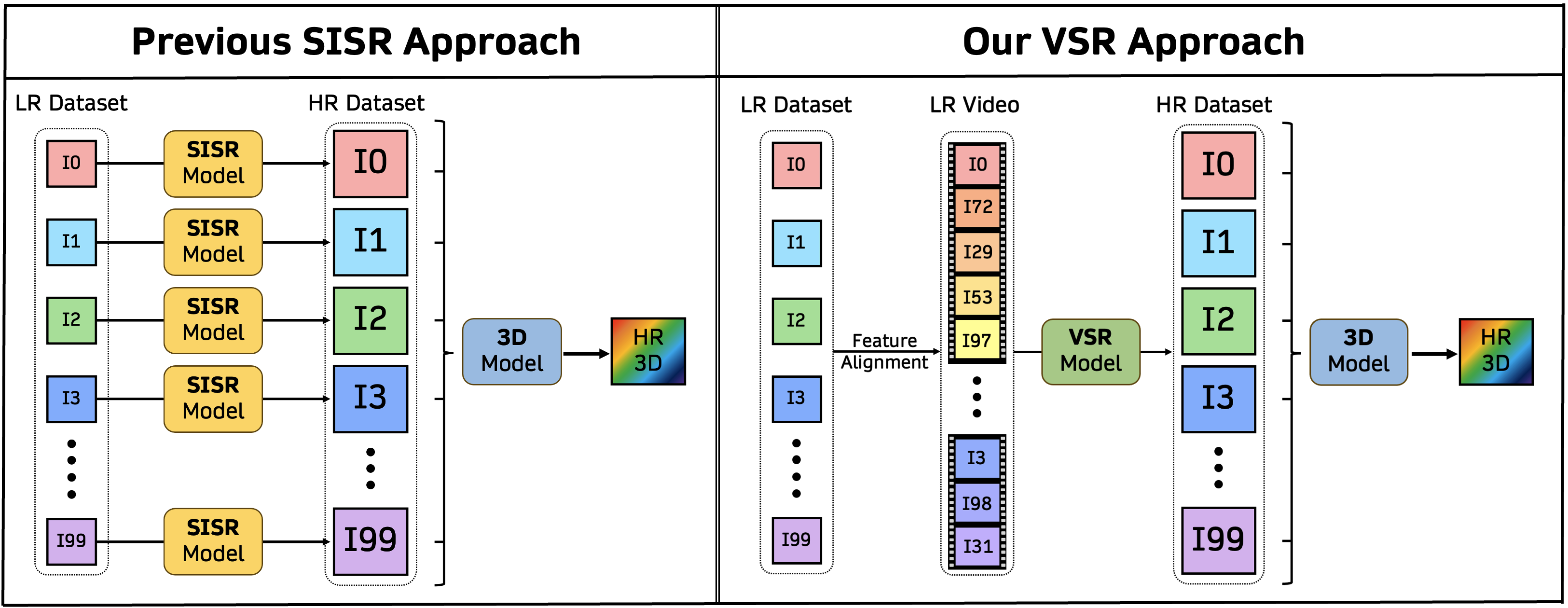
In previous studies, SISR (Single Image Super-Resolution) models individually upsampled each LR (low-resolution) multi-view image in separate runs. As a result, the upsampled images lack 3D consistency, leading to blurry details.
On the other hand, using VSR (Video Super-Resolution) for 3D super-resolution tasks ensures that the temporal consistency in videos aligns the 3D spatial consistency to some extent. This not only improves view-to-view consistency but also gathers information from other views to enable more accurate and precise reconstruction.
*click the video to play again!
SuperGaussian (1) is the only study that uses VSR models for 3D Super-Resolution. This model first constructs a low-resolution (LR) 3D representation through LR training and then renders smooth videos, which are fed as input to the VSR model.
However, this approach introduces unintended stripy and blob-like artifacts caused by Gaussian splats during the LR 3D training process in 3DGS. Consequently, the rendered videos deviate from the degradation that the VSR model expects, requiring extensive retraining of the VSR model.
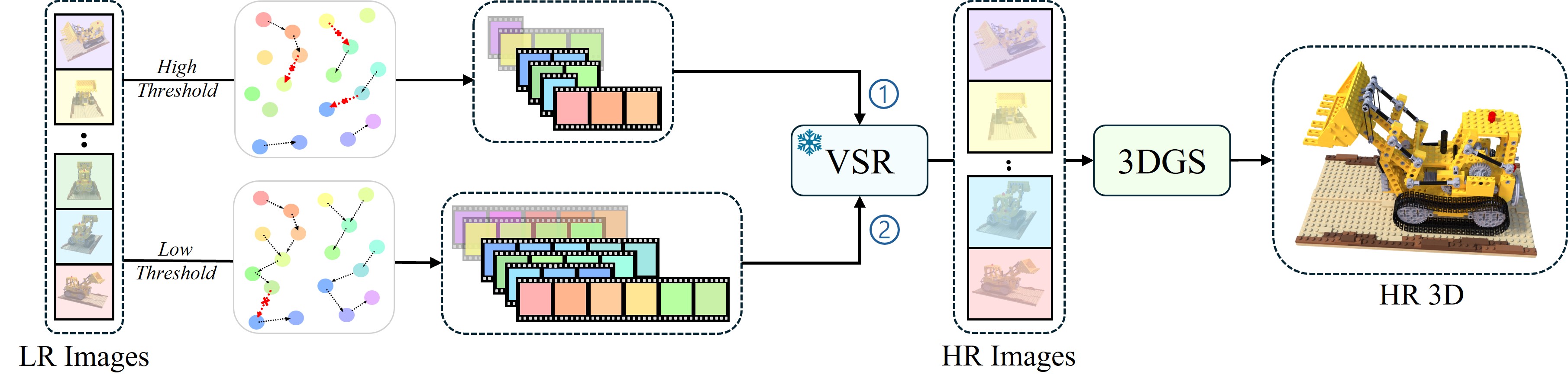
Our approach (2) focuses on stitching the raw LR dataset into a video-like sequence without any transformation. By greedily connecting images with the closest feature or pose similarity, we can generate a video-like sequence from sparse data. This sequence is then used as input for the VSR model to perform upsampling.
This method allows us to use pretrained VSR models directly without modification while effectively addressing the aforementioned artifacts, resulting in significantly better performance. The artifacts of LR training is shown below.
Indirect refers to VSR output with rendered low-resolution 3DGS as input, and Direct represents direct inference of given low-resolution GT. Performance degradation is due to distribution shift between rendered LR splats and GT LR data.
Our method comprises adaptive-length sequencing, which organizes unordered low-resolution (LR) images into structured "video-like" subsequences. Starting from each image as an initial frame, the algorithm incrementally selects subsequent frames based on similarity measures, such as pose or visual features, until a predefined threshold is met. This process creates multiple subsequences of varying lengths that maintain smooth transitions between adjacent frames. These ordered subsequences are then fed into a pre-trained video super-resolution (VSR) model, which utilizes the temporal coherence between frames to upsample the LR sequences into high-resolution (HR) images. The resulting HR images are subsequently used to train a 3D Gaussian Splatting (3DGS) model, ensuring high-fidelity 3D reconstruction with enhanced spatial and multi-view consistency.
NeRF Synthetic Dataset
| Method | PSNR↑ | SSIM↑ | LPIPS↓ |
|---|---|---|---|
| Bicubic | 27.56 | 0.9150 | 0.1040 |
| SwinIR | 30.77 | 0.9501 | 0.0550 |
| Render-SR | 28.90 | 0.9346 | 0.0683 |
| NeRF-SR | 28.46 | 0.9210 | 0.0760 |
| ZS-SRT† | 29.69 | 0.9290 | 0.0690 |
| CROP† | 30.71 | 0.9459 | 0.0671 |
| FastSR-NeRF† | 30.47 | 0.9440 | 0.0750 |
| DiSR-NeRF | 26.00 | 0.8898 | 0.1226 |
| SRGS† | 30.83 | 0.9480 | 0.0560 |
| Gaussian-SR† | 28.37 | 0.9240 | 0.0870 |
| SuperGaussian† | 28.44 | 0.9459 | 0.0670 |
| Ours | 31.41 | 0.9520 | 0.0540 |
The numbers marked with † are sourced from their respective paper, as the code is not available at this time.

To compare baselines, select a Baseline + Object pair from the dropdown menu.
Then, choose a Region (e.g., center or corner) to view and compare the zoomed-in area for each baseline.
@article{ko2024sequence,
title={Sequence Matters: Harnessing Video Models in Super-Resolution},
author={Ko, Hyun-kyu and Park, Dongheok and Park, Youngin and Lee, Byeonghyeon and Han, Juhee and Park, Eunbyung},
journal={arXiv preprint arXiv:2412.11525},
year={2024}
}